📌 프로젝트 개요
☐ 주관 : BOAZ 시각화 21기 미니프로젝트
☐ 프로젝트 명 : VENENO 광고 타겟팅 최적화를 위한 인사이트 대시보드
☐ 프로젝트 기간 : 23년 10월 ~ 23년 12월
☐ 인원 : 4명 (BOAZ 시각화 3차 미니프로젝트, 팀 베네보)
☐ 활용 Tool : Notion, Python, Selenium, Tableau, PPT
☐ 프로젝트 개요 : VENENO의 효율적인 광고 운영 및 수익 극대화를 목적으로 데이터 분석을 통해 인사이트를 도출하여 최적 광고 기획을 제안
☐ 본인이 맡은 역할 :
- 자료 수집 및 전처리 :
- Selenium을 이용하여 VENENO 상품 리뷰 크롤링
- TF-IDF를 사용하여 각 상품에 맞는 키워드 선별
- 대시보드 제작
- 발표
☐ 성과/의의 :
- Naver Analytics 데이터 분석을 통해 가장 방문자가 많은 시간대/요일 등 파악 가능
- 리뷰 데이터 크롤링 및 분석을 통해 타겟팅에 유리한 방법 제공
📑 프로젝트 내용
❓주제 선정 배경
브랜드 veneno는 효율적인 광고 운영 및 수익 극대화를 목적으로 광고 홍보를 진행하고 있었습니다. 데이터 기반 의사결정이 아닌 감으로 키워드를 선정하여 광고에 투입하였고, 네이버 Analytics 데이터를 한 눈에 확인할 수 있는 대시보드가 필요하였습니다.
이를 해결하기 위해, 크게 다음 두 가지의 목표를 세웠습니다.
- 네이버 Analytics 데이터를 통한 인사이트
- 주력 상품 리뷰 분석을 통한 인사이트
를 중점으로 두고, 데이터 분석을 통해 광고 키워드 위주로 효과적인 광고 수립에 도움을 주고자 합니다.
🔗 데이터 수집
📈 활용 데이터 목록
데이터 | 시점 | 출처 | 데이터 설명 및 목적 |
월별 검색채널 방문 분포 | 2022.11 ~ 2023.11 | veneno 네이버 Analytics | [PAGE VIEW & VISITOR ANALYSIS] 검색 채널 방문 분석 |
월별 유입검색어 TOP 100 | 2022.11 ~ 2023.11 | veneno 네이버 Analytics | [WEBSITE TRAFFIC SOURES ANALYSIS] 유입 키워드 분석 |
일별 종합 데이터 | 2022.11 ~ 2023.11 | veneno 네이버 Analytics | [PAGE VIEW & VISITOR ANALYSIS] [TIME SERIES ANALYSIS] ## 대시보드 켜서 알아볼 것! |
연월별 종합 데이터 | 2022.11 ~ 2023.11 | veneno 네이버 Analytics | [PAGE VIEW & VISITOR ANALYSIS] [TIME SERIES ANALYSIS] ## 대시보드 켜서 알아볼 것! |
주력 상품 리뷰 데이터 | * 상품별 상이 | veneno 상품 리뷰 | [REVIEW CRAWLING & KEYWORD ANALYSIS] 상품 리뷰 리스트 생성 |
주력 상품별 키워드 TOP 50 | * 상품별 상이 | veneno 상품 리뷰 | [REVIEW CRAWLING & KEYWORD ANALYSIS] 상품 리뷰 키워드 생성 |
활용한 모든 데이터는, 프로젝트 진행 당시 기준 최신 데이터로 수집하였습니다.
🙋🏻♀️ 본인이 맡은 역할
⓵ 리뷰 크롤링할 상품 선정 및 키워드 분석 아이디어 제시
리뷰 크롤링할 상품을 선정에 대한 아이디어를 제안하였습니다.
주력 상품 선정- 정의 : 주력 상품이란, 가장 판매에 공을 들이고 있어 많은 고객을 모을 수 있는 상품
- 선택 : veneno의 모든 상품에 대한 리뷰를 크롤링 하기에는 프로젝트 진행 기간 상 한계가 있었기에, 누적판매순 & 리뷰많은순을 기준으로하여 5개씩 총 10개를 선정
no. | 누적판매/리뷰많은순 | 제품이름 |
1 | 리뷰많은순 | [라이브특가] [12colors/무배] 촘촘짜임 소프트무지 가을겨울 니트 머플러 목도리 |
2 | 리뷰많은순 | [라이브특가] 크리스탈 더블더블 스톤귀걸이 |
3 | 리뷰많은순 | 기본 컬러스톤 은침귀걸이 [30컬러] |
4 | 리뷰많은순 | [베네노제작] 16SET 프린세스 큐빅 은볼 진주 세트 귀걸이 (실버,골드,큐빅,진주,링,체인) |
5 | 리뷰많은순 | [라이브특가] [7colors/무배] 부들부들 미니 가을겨울 니트 머플러 목도리 |
6 | 누적판매순 | 틴 넓은챙 사이즈조절 투톤 밀짚 햇빛차단 썬캡 여름모자5% 할인 |
7 | 누적판매순 | [2colors] 와이어 린넨 리본끈 넓은챙 햇빛차단 벙거지 여름모자 |
8 | 누적판매순 | [무배] 실버925 메르 볼드 투톤 스크레치 원터치 링 귀걸이 |
9 | 누적판매순 | [베네노제작] 925실버 최고급 못난이 천연 담주진주 귀걸이 |
10 | 누적판매순 | [라이브특가] [6colors] 배색 끝단 사계절용 부드러운 머플러 스카프 |
⓶ 정해진 상품 리뷰 크롤링
총 10개의 상품에 대해서 리뷰를 추출하고, 빈도 수가 많은 키워드를 추출하였습니다.
리뷰 추출아래 코드는, 총 10개의 상품의 대해 긍정적인 키워드를 추출하기 위한 리뷰 데이터 수집 과정입니다.
- 라이브러리 불러오기
import time from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options import pandas as pd from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import re from selenium.webdriver import ActionChains from konlpy.tag import Okt from collections import Counter from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity, pairwise_distances_argmin_min from sklearn.metrics.pairwise import cosine_similarity from sklearn.cluster import KMeans import numpy as np import math
- 크롬 드라이버 실행
chrome_options = Options() driver = webdriver.Chrome() URL = 'https://smartstore.naver.com/veneno/products/()' # 괄호 지우고, 페이지 고유 번호 작성 driver.get(URL) # 리뷰, 별점 크롤링 while count < stop: for pagenum in next_btn: driver.find_element(By.CSS_SELECTOR, '#REVIEW > div > div._180GG7_7yx > div.cv6id6JEkg > div > div >'+str(pagenum)+'').click() html = driver.page_source soup = BeautifulSoup(html, "html.parser") reviews = soup.find_all('div', class_='_19SE1Dnqkf') ratings = soup.find_all('em', class_='_15NU42F3kT') for review, rating in zip(reviews, ratings): review_text = re.sub('[^#0-9a-zA-Zㄱ-ㅣ가-힣 ]', "", review.text) rating_text = rating.text review_list.append([review_text, rating_text]) count += 1 # 카운트 증가 # 텍스트 전처리 및 별점 4, 5점만 남기기 df = pd.DataFrame(review_list, columns=['리뷰', '별점']) df = df.drop_duplicates() df = df[(df['별점'] == '5') | (df['별점'] == '4')]
- 리뷰 수 입력
상품 총 리뷰 수 확인 후, 그대로 입력해 줍니다.
from selenium import webdriver count = 0 stop = int(input("전체 리뷰 수를 입력해주세요 ")) next_btn = ['a:nth-child(2)', 'a:nth-child(3)', 'a:nth-child(4)', 'a:nth-child(5)', 'a:nth-child(6)', 'a:nth-child(7)', 'a:nth-child(8)', 'a:nth-child(9)', 'a:nth-child(10)', 'a:nth-child(11)', 'a.fAUKm1ewwo._2Ar8-aEUTq'] review_list = [] star_list = []
- 리뷰, 별점 크롤링
while count < stop: for pagenum in next_btn: driver.find_element(By.CSS_SELECTOR, '#REVIEW > div > div._180GG7_7yx > div.cv6id6JEkg > div > div >'+str(pagenum)+'').click() html = driver.page_source soup = BeautifulSoup(html, "html.parser") reviews = soup.find_all('div', class_='_19SE1Dnqkf') ratings = soup.find_all('em', class_='_15NU42F3kT') for review, rating in zip(reviews, ratings): review_text = re.sub('[^#0-9a-zA-Zㄱ-ㅣ가-힣 ]', "", review.text) rating_text = rating.text review_list.append([review_text, rating_text]) count += 1 # 카운트 증가
- 텍스트 전처리 및 별점 4/5점만 남기기
3점 이하의 별점은 긍정적인 리뷰가 아니라고 생각하여 추천 키워드를 뽑아낼 수 없다고 판단하였습니다.
df = pd.DataFrame(review_list, columns=['리뷰', '별점']) df = df.drop_duplicates() df = df[(df['별점'] == '5') | (df['별점'] == '4')] def remove_special_and_specific_text(text): text = re.sub(r"[^\uAC00-\uD7A30-9a-zA-Z\s]", "", text) # 특수 문자 제거 text = text.replace('한달사용기', '') # '한달사용기' 문자열 제거 return text df['리뷰'] = df['리뷰'].apply(remove_special_and_specific_text) df = df.sort_values(by='별점', ascending=False).reset_index(drop=True) df
- 불용어 제거
stopwords = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/korean_stopwords.txt").values.tolist() add_stopwords = [] # 아래 코드 돌려보고 추가해야하는 불용어 추가하기 for word in add_stopwords: stopwords.append(word) stopwords
- 리뷰별 형용사/명사 추출
형용사/명사가 키워드 추출에 적당하다고 판단하였습니다.
okt = Okt() # Okt 형태소 분석기 객체 생성 def extract_nouns_and_adjectives_from_review(text): morphs = okt.pos(text) # 형태소 분석하여 품사 태깅 nouns = [word for word, pos in morphs if pos in ['Noun']and word not in stopwords] # 명사 추출 adjectives = [word for word, pos in morphs if pos in ['Adjective']and word not in stopwords] # 형용사 추출 return nouns, adjectives df['명사_추출'], df['형용사_추출'] = zip(*df['리뷰'].apply(extract_nouns_and_adjectives_from_review)) df['명사_형용사_추출'] = df['명사_추출'] + df['형용사_추출'] df
- 상품명 추가하기
review = df['리뷰'] review_df = pd.DataFrame(review) review_df['상품명'] = '' # 적절한 상품명으로 설정 new_order = ['상품명', '리뷰'] review_df = review_df[new_order] review_df
빈도 수 상위 50개 키워드 추출아래 코드는, 위의 코드에 이어서 총 10개의 상품의 대해 대표 키워드를 추출하기 위한 빈도 수 상위 50개 키워드 데이터 수집 과정입니다.
- 전체 리뷰 대상 빈도 수 상위 50개 단어 추출
word_counter = Counter() for word_list in df['명사_형용사_추출']: word_counter.update(word_list) top_50_words = word_counter.most_common(70) top_50_df = pd.DataFrame(top_50_words, columns=['단어', '빈도수']) top_50_df = top_50_df[top_50_df['단어'].apply(lambda x: len(str(x))) > 1] top_50_df['상품명'] = '' # 적절한 상품명으로 설정 new_order = ['상품명', '단어', '빈도수'] top_50_df = top_50_df[new_order] top_50_df = top_50_df.head(50) top_50_df
💡성과/의의
📍대시보드 인사이트
제작한 총 4개의 대시보드별 인사이트는 다음과 같습니다.

PAGE VIEW & VISITOR ANALYSIS
- 1년 동안의 신규 방문자와 재 방문자의 비율에 따르면 신규 방문자의 비율이 50% 이상
- 재 방문자 수의 비율은 적지만, 월별로 꾸준히 방문
- 겨울부터 초여름까지(12월 ~ 6월)의 방문자 수가 높은 것으로 보아, 겨울/봄/초여름 시즌 상품에 소비자들이 적극 반응함
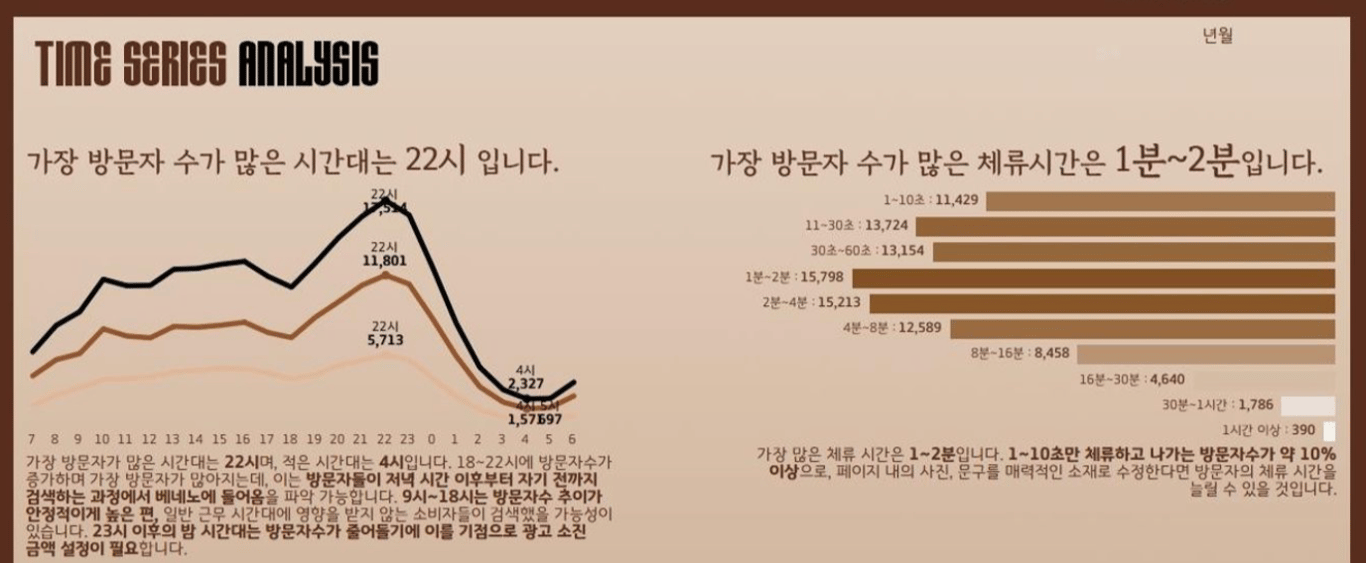
TIME SERIES ANALYSIS
- 가장 방문자가 많은 시간대는 22시, 적은 시간대는 04시
- 18~22시에 방문자수가 증가하며 가장 방문자가 많아지고, 이는 방문자들이 저녁 시간 이후부터 자기 전까지 검색하는 과정에서 베네노에 들어옴을 예측할 수 있음
- 09시~18시는 방문자수 추이가 안정적이게 높은 편
- 가장 많은 체류 시간은 1~2분. 체류시간이 짧으므로 페이지 내의 사진, 문구를 매력적인 소재로 수정한다면 방문자의 체류 시간을 늘릴 수 있을 것이라 예상

WEBSITE TRAFFIC SOURCES ANALYSIS
- 검색으로 들어온 유입이 광고로 들어온 건수에 비해 약 2배 많음
- 베네노의 유입 키워드를 확인했을 때, 여름모자 → 머플러 → 귀걸이 → 목도리 → 베네노 순으로 많음. 해당 상품을 대상으로 홍보에 주력한다면, 더 많은 매출 상승으로 이어질 수 있을 것이라 예상
- 네이버 포털 사이트 혹은 네이버 쇼핑 사이트에서 veneno로 유입되는 경로가 많은 편

REVIEW CRAWLING & KEYWORD ANALYSIS
- 상품 사진 선택 시, 해당 상품의 리뷰와 상품 키워드 Best 50을 확인 가능
- 추가로, 상품별 추천 키워드를 5개씩 제공
📍대시보드 의의
제작한 총 4개의 대시보드 의의는 다음과 같습니다.
- Naver Analytics 데이터를 기반으로 한 veneno 맞춤 대시보드
- veneno에서 자주 확인하는 데이터들을 한 눈에 파악할 수 있는 대시보드가 필요하여, 이를 중점으로 두고 대시보드를 제작하였습니다.
- Naver Analytics에서는 제공되지 않는 상세한 부연 설명을 대시보드에 함께 넣어 대시보드를 제작하였습니다.
- 상품 리뷰 크롤링 및 주요 키워드 선정
- 주력 상품의 주요 키워드를 선정하기 위해 동적 크롤링을 사용하여 리뷰 데이터를 수집하였습니다.
- 주력 상품의 리뷰 데이터를 텍스트 분석을 활용하여, 홍보에 필요한 주요 키워드를 선정하였습니다.
💬 회고
➕ 보완할 점
- 브랜드 대표님께서, Naver Analytics에서 제공되는 데이터 위주로 유의미하게 자주 확인하시는 데이터로 대시보드를 구성했는데, 조금 더 다양한 데이터 혹은 지표를 구성하여 대시보드를 만든다면 더욱 풍부한 대시보드가 될 것이라 예상합니다.
- 주요 키워드를 선정하기 위한 분석 작업이 고도화되지 않아, 이를 고도화된 분석을 실시한다면 더욱 정확한 키워드 추천이 될 것이라 예상합니다.
🚶🏻♀️➡️ 성장한 점
- 지난 프로젝트 때 크롤링 관련 애로사항을 해결하여 진행한 프로젝트라서, 의미가 깊었던 시간이었습니다.
- 현업에서 사용되는 데이터를 직접 만지며 분석할 수 있어, 의미가 깊었던 시간이었습니다.
 Made with Bullet
Made with Bullet